DB 로직 최소화를 하려면 어떻게 해야 할까요
DB 로직을 최소화하는 것은 성능을 향상시키고 유지 보수를 간소화하는 데 도움이 됩니다.
예를 들어, 이러한 방법으로 DB 로직을 최소화할 수 있다.
EX.
일관된 데이터 모델링:
데이터베이스 테이블과 엔테테를 일관성 있게 설계하고
중복 데이터를 줄이고 일관성을 유지하여 데이터 중복을 최소화화고 무결성을 유지한다.
비즈니스 로직 최적화:
데이터베이스에서 비즈니스 로직을 수행하기보다는 비즈니스 로직을 애플리케이션 레벨에서 처리한다.
데이터베이스는 데이터 저장과 관리에 중점을 두는 것이 좋다.
캐싱:
반복적으로 동일한 데이터를 검색해야 하는 경우,
검색 결과를 캐시하여 데이터베이스 요청을 최소화할 수 있다.
배치 작업:
대량의 데이터를 처리해야 할 때는 배치 작업을 사용하여,
데이터베이스 부하를 최소화할 수 있다.
프로파일링과 모니터링:
데이터베이스 성능을 모니터링하고,
쿼리 실행 계획을 분석하여 병목 현상을 파악하고 최적화 작업을 수행한다.
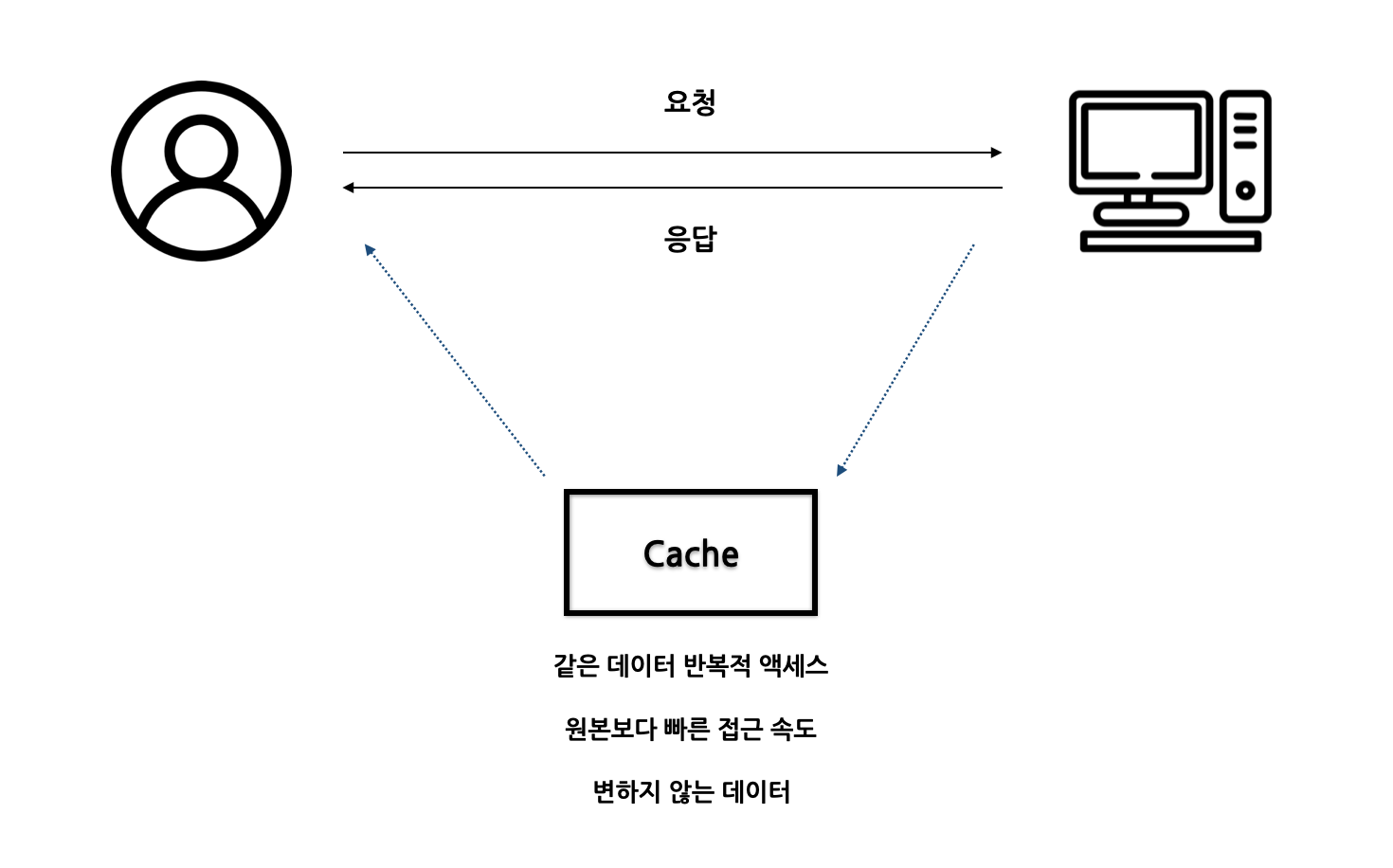
db 캐싱 개념
Cache
Cache는 데이터나 값을 저장하는 임시 저장소로, 데이터를 더 빠르고 효율적으로 액세스할 수 있게 해준다.
- 원본 데이터 접근보다 빠르다.
- 같은 데이터를 반복적으로 접근하는 상황에서 사용하기에 알맞다.
- 인증 세션 값과 같은 잘 변하지 않는 데이터일수록 더 효율적이다.
CPU Cache
레이어별로 캐시를 보면 용량은 위로 갈수록 커지고 속도로 밑으로 내려갈수록 빨라진다. 보통 우리가 사용하는 Redis는 Memory층에 존재한다고 보면 된다.
- Disk가 제일 느리고 L3 < L2 < L1 순으로 속도가 빠르다.
- Disk 접근 속도가 SSD를 쓰고있지만 Memory와 비하면 속도가 굉장히 차이난다. 그렇기 때문에 Memory에 올려놓고 쓰는 게 Disk에서 읽어오는 것보다 훨씬 빠르다. 그 대신 용량은 당연히 Disk가 훨씬 크다.

CPU Cache
추상적인 웹 서비스 구조 (클라이언트 - 웹 서버 - DB)
클라이언트가 웹 서버에 접속하고 요청을 보내면 웹 서버가 DB에 데이터를 읽거나 쓰기 작업을 요청한다. DB도 사실 내부용 캐시가 있지만 캐시 용량이 Memory 사이즈보다 커지면 당연히 Disk를 사용해야 한다. 쿼리 결과를 내부적 캐시에 담고 있는데 여러가지 요청을 처리하다 보면 기존에 있던 캐시를 날리고 디스크에서 새로 읽어야 하는 순간이 온다. 그래서 디스크에 접근할 때마다 속도가 굉장히 느려질 수 있다.

Cache 구조 및 전략
Redis로 캐시로 사용할 때 어떻게 배치할 것이냐는 캐싱 전략이 필요하다. 이에 따라 성능에 영향을 끼치기 때문에 상황(데이터 유형, 데이터 액세스 패턴)에 맞게 적절한 전략을 사용해줘야 한다.
- 시스템이 많이 작성하는데 덜 자주 읽습니까? (ex. 시간 기반 로그)
- 데이터를 한번 쓰고 여러 번 읽습니까? (ex. 사용자 프로필)
- 반환되는 데이터는 항상 고유합니까? (ex. 검색어)
'Study > 개발일지' 카테고리의 다른 글
| [백엔드TIL] Spring security 로그인 실패 시 예외처리 방식(78일차) (0) | 2023.09.18 |
|---|---|
| [백엔드WIL] DB캐싱 (16주차) (0) | 2023.09.15 |
| [백엔드TIL] Mockito를 활용한 단위테스트 (76일차) (0) | 2023.09.14 |
| [백엔드TIL] Spring 구조와 DDD 개발(75일차) (0) | 2023.09.13 |
| [백엔드TIL] Docker 설정하면서 트러블슈팅(74일차) (0) | 2023.09.12 |


