이번 프로젝트에서 Spring boot + JPA + Gradle 을 적용하면서 헷갈렸던 부분, 알게 된 부분에 대해서 적기 위해 작성했습니다.
JPA 강의를 듣고 적용하는 과정에서 Maven말고 Gradle로 프로젝트를 진행했는데, 다른 점이 있다보니 조금 헤맸습니다.
👀 의문점 발생.
- JPA 강의에서 persistence.xml을 작성하고 Entity Manager를 생성한다음 JPA 작성을 하는데, Gradle은 xml을 쓰지 않는 것을 장점으로 알고있다.
(pom.xml대신 build.gradle를 작성한다) - Gradle로 작성할 때 application.properties에 JPA 속성을 작성했기 때문에 persistence.xml을 작성하면 중복 작성이 된다.
- Gradle + JPA을 검색해보니 강의에서 사용한 em.persist 구조가 아닌, JpaRepository를 상속한 interface를 작성하여 사용한다.
✏️ 코드 검증 및 작동방식 이해
먼저 Gradle에서 META/persistence.xml을 작성해도 정상적으로 작동하는지 확인해보기로 했습니다.
start.spring.io에서 프로젝트를 다음과 같이 생성한다음

(Gradle로 생성, Spring Data JPA dependency 추가)

- mysql을 사용하기 위해 추가로 mysql-connector-java dependency를 추가합니다.
강의에서 사용했던 EntityManager를 사용하기 위해 persistence.xml을 다음과 같이 작성했습니다.
(resources/META-INF/persistence.xml)
작성을 마치고 main함수를 실행했더니 오류가 발생했습니다.

여기서 내가 알고 있는 뭔가가 잘못됐다는 것을 직감했습니다.
강의에서는 hibernate를 사용했고, 저는 Spring Data JPA를 사용하는데 이 둘이 다르다는 것을 이 때 알았습니다.
그러면 먼저 해결 할 문제가 남았습니다.
JPA와 Hibernate의 차이는 정확히 뭐지?
* JPA
JPA는 Java Persistence API의 약자로, 스프링에서 제공하는 것이 아닌 자바 어플리케이션에서 관계형 디비를 사용하는 방식에 대해 정의한 인터페이스이다.
즉, JPA는 특정 기능을 수행하는 라이브러리 같은 개념이 아니라 서버 동작 방식이나, API가 동작하는 방식을 설명하는 것처럼 개념을 정의한 것이었습니다.
JPA는 JAVA에서 제공하는 단순한 명세이기 때문에 이에 대한 구현은 없습니다.
* Hibernate
JPA 자체는 인터페이스이기 때문에 우리는 이를 구현해서 실제로 동작하게 해야합니다. 이를 제공하는게 바로 Hibernate 였습니다.
JPA를 사용하기 위해서는 Hibernate 말고 DataNucleus, EclipseLink와 같은 다른 방법으로 사용 할 수 있습니다.
- 요약: JPA는 기술명세이고, Hibernate는 JPA의 구현체이다.
위의 내용을 정확히 인지하고 현재 직면한 문제를 보니, 무엇을 공부하고 고쳐야 하는지 바로 알 수 있었습니다.
- Spring Data JPA와 Hibernate의 차이
- Gradle에서 Hibernate를 사용하면 xml을 사용?
😲 Spring Data JPA vs Hibernate
위의 내용을 토대로 Spring Data JPA, Hibernate 모두 JPA의 구현체인 것은 짐작 할 수 있었습니다. 그럼 둘의 차이점을 알아야 했습니다.
* Spring Data JPA
Spring Data JPA는 공식 문서를 참고하면 쉽게 정보를 얻을 수 있었습니다.
인터넷에서 찾아봤던 Repository를 생성하고 메소드 이름 규칙을 따르면 쉽게 JPA를 사용할 수 있는 것이 바로 Spring에서 제공한 Spring Data JPA를 사용했기 때문이었습니다.
ex)
interface UserRepository extends JpaRepository<User, Long> {
long deleteByLastname(String lastname);
List<User> removeByLastname(String lastname);
}JpaRepository를 상속해서 JPA를 구현하는 방식이 Spring Data JPA 방식입니다.
JpaRepository의 내부적으로 확인해보면


이런식으로 우리가 Hibernate에서 사용했던 "EntityManager"를 사용하고 있는 것을 확인 할 수 있었습니다.
* Hibernate
Hibernate는 Hibernate 공식문서를 참고하면 META-INF/persistence.xml을 정의하고, JPA를 사용 할 수 있다고 나와있습니다.

여기에 정의한 것을 EntityManager로 생성 할 수 있습니다.
즉, Gradle이든 Maven이든 어떤 JPA 구현체를 사용하냐에 따라 구현 방법의 차이가 있었던 것이었습니다. 실제로 Gradle + Hibernate를 사용하면 persistence.xml을 사용해도 상관 없었습니다.
-> pom.xml대신 build.gradle에서 groovy를 사용하면서 장점이 있는 것이지 xml을 아예 사용하지 않는 것은 아니었습니다 ㅎㅎ;
🙌 해결
정리하자면
- Spring Data JPA 사용
application.properties에 정의
CRUDRepository, JpaRepository를 상속해서 JPA 구현. -> 네이밍 규칙 있음 (네이밍 규칙)
+ EntityManager를 사용하려면 @PersistenceContext 통해 사용가능.
@PersistenceContext
private EntityManager em;
public User insertUser(User user){
em.persist(user);
return user;
}- Hibernate 사용
resources/META-INF/persistence.xml에 정의
EntityManagerFactory에서 EntityManager 생성.
EntityManager로 각 클래스에 맞춰서 코딩. - Gradle에서 xml을 아예 사용하지 않는 것은 아니다.
번외
시글에 대한 ‘좋아요’ 기능인데요, 현재 구조에서는 게시글을 조회할 때, ‘좋아요’ 테이블과 함께 조인을 해서 가져오고 있습니다. 단순히 좋아요 개수만 저장하지 않는 이유는, 한번 좋아요 버튼을 누른 사람은 두 번째 누를 때 취소할 수 있어야 하기 때문입니다.
하지만 이런 방식이라면 만약 게시글 하나에 좋아요가 100만개가 된다면 게시글을 조회 한번 할때마다 100만개를 조인하게되어 오버헤드가 커지게 됩니다. 실제로 유튜브, 인스타의 경우 좋아요 개수가 100만개를 훌쩍 넘는 경우가 많은데요, 어떻게 이런 문제를 처리할 수 있는지 궁금했습니다. 현재 속닥속닥에는 ‘좋아요’ 개수가 딱 정확하게 나와야 하는 비즈니스적 요구 사항은 없지만, 게시글의 성격에 따라 충분히 발생할 수 있는 요구사항이라고 생각했습니다.
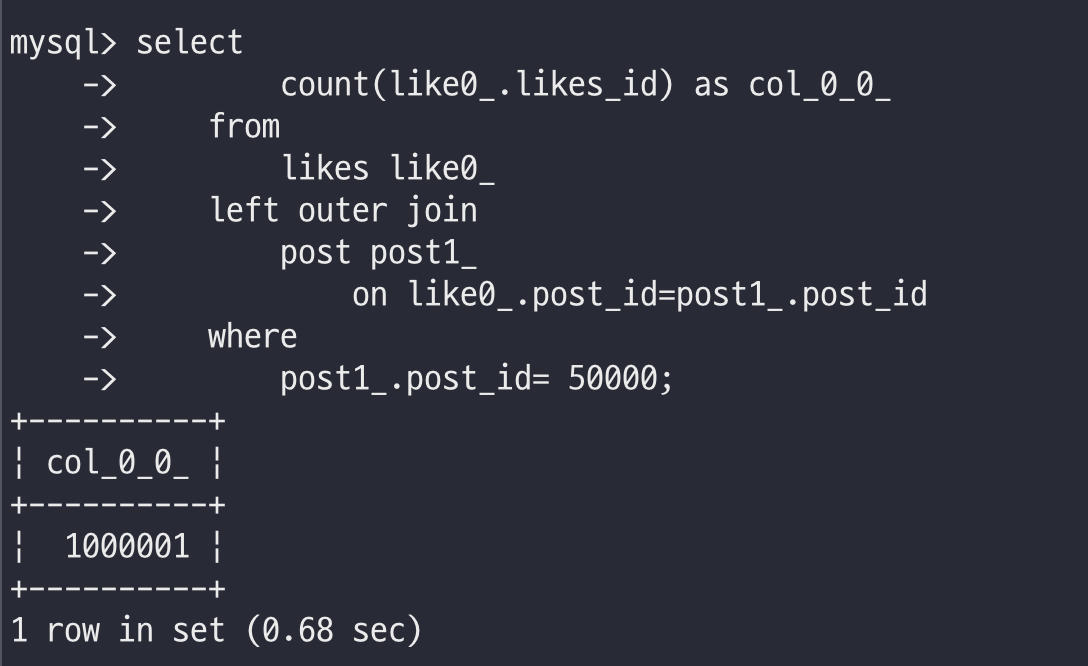
실제로 저희가 테스트를 해본 결과 게시글의 좋아요 개수를 조회하는데에만 0.68초가 걸렸습니다.


그래서 저희는 반정규화를 선택했습니다. post 테이블에 like_count 컬럼을 추가함으로서 likes 테이블을 조인하지 않고도 해당 게시글의 좋아요 개수를 알 수 있습니다. 이렇게 해서 해당 게시글의 좋아요 개수를 가져오는데 시간을 0.0013으로 줄일 수 있었습니다.
하지만 이렇게 되면 좋아요 개수에 대한 정보가 두 테이블에 나타나게 되어 데이터 정합성을 맞추는 것이 중요한 문제가 됩니다. 데이터 정합성이 안맞는다는 말에 대해 풀어보자면, 좋아요를 누를때는 like 테이블에서 삽입, 삭제가 일어나게 되는데, post 테이블의 like_count 에 대해서도 수정을 해주어야 됩니다. 한 가지 데이터에 대해, 두 테이블에서 수정이 이루어지니 데이터가 맞지 않을수도 있게 됩니다.
예를 들어 A 사용자가 좋아요를 누른다면, likes 테이블에 삽입을 해주고, post 테이블의 likecount에 기존 likecount + 1을 해줍니다. 그런데, 이 트랜잭션이 커밋되기 전에 B 사용자가 좋아요를 누른다면, 변화된 likecount 에 + 1 을 해주는 것이 아니라, 커밋되기 전 상태의 likecount에 + 1 을 해주어 데이터가 맞지 않게 되는 것입니다. 다시 말해, 좋아요가 0개인 상태에서 2명이 좋아요를 눌렀으므로 2개가 되어야 하는데, 1 개가 되는 것입니다. 이를 갱신 분실(Lost Update)라고 합니다.


화면 왼쪽은 A 트랜잭션, 오른쪽은 B 트랜잭션입니다. 자바 코드로 예시를 작성할 수도 있지만 보다 직관적으로 트랜잭션의 흐름을 보기 위해 MySQL 쿼리로 예시를 만들어봤습니다. 이 트랜잭션은 좋아요 개수를 조회하고, 좋아요의 개수를 1 증가하는 쿼리입니다. 처음 post의 likecount에는 1,000,001개의 데이터가 있었으므로 두 트랜잭션이 정상적으로 실행됐으면 1,000,003개가 되어야합니다. 하지만 A 트랜잭션에서 4번째 줄까지 실행하고 B 트랜잭션이 나머지를 실행하면 likecount는 1,000,002개로 하나의 write 요청이 다른 요청에 의해 덮어쓰여진 것을 알 수 있습니다.
1. Lock


첫번째로 락을 거는 방법을 생각했습니다. 조회 쿼리에 락을 걸어 데이터 정합성을 맞추는 것이죠. A 트랜잭션이 likecount 를 변경하는 업데이트 작업을 하고 커밋을 할 때 까지 B 트랜잭션은 likecount에 대한 조회에 대한 접근이 불가능합니다. 결과적으로 A 트랜잭션이 커밋 되고 나서 B 트랜잭션은 likecount를 얻기 때문에 정확한 likecount 데이터에서 1을 더하게 되고, 데이터 정합성이 맞게 됩니다. 기존 100,001 개의 좋아요 개수에서 두 트랜잭션이 커밋된 후에 100,003 개가 된 것을 볼 수 있습니다.
하지만, 락을 거는 방법은 서비스의 확장성을 고려했을 때 적절하지 않다고 생각했습니다. 조회에 대한 락을 걸게 되면 트랜잭션이 끝나는 것을 다 기다려야 하기 때문에 성능이 매우 나빠지게 될 것이기 때문입니다.
2. Native Query

두번째 방법은 네이티브 쿼리를 이용해 post 테이블의 like_count 데이터 자체를 읽어 1을 더해주는 것입니다. update 명령어는 그 자체로 atomic 합니다. 따라서 값을 읽고 그 읽은 값을 증가시키는 과정을 분리하지 않고 한번에 업데이트 하도록 하면 동시성 문제를 해결할 수 있습니다.
하지만, 한 트랜잭션이 업데이트를 진행하고 있는 경우에는 다른 트랜잭션에서 해당 row에 대해서는 update 작업을 하지 못합니다. 게시글 수정같이 업데이트가 빈번하지 않은 작업이라면 괜찮겠지만, 좋아요는 클릭 한번으로 수정이 되는 변경이 쉬운 작업입니다. 여러 사용자가 동시에 좋아요를 여러번 누르는 상황이 발생한다면, 서버에 무리가 갈 것이라고 판단되었습니다.
3. Sync Schedule
세번째 방법은 특정 주기마다 좋아요 개수를 맞추어 주는 것입니다. 처음에 문제였던 것이 동시에 사용자 요청이 들어올 때 같은 likecount 를 얻어 좋아요 개수가 맞지 않는다는 것인데, 이렇게 맞지 않았던 데이터를 주기적으로 한번씩 맞추어 주는 것입니다. likecount 는 데이터가 정확하지 않더라도, like 테이블을 통해서 정확한 좋아요 개수를 얻을 수 있기 때문에 가능한 방법입니다. 이 방법을 사용한다면 like_count 에 대한 접근을 할 때 다른 트랜잭션이 커밋되기를 기다리지 않아도 되기 때문에 성능적으로 이점이 있습니다.
그러나 매 주기마다 데이터 정합성이 맞추어 지기는 하지만, 업데이트 주기가 오기 전까지는 데이터가 맞지 않을 수 있기 때문에, 정확한 좋아요 개수를 요구하지 않는 환경에서 사용하기에 좋다고 생각됩니다. 이렇게 시간이 지나서 최종적으로 같은 데이터로 동기화하는 것을 궁극적 일관성(Eventual Consistency)라고 합니다.

실제 인스타나 유튜브를 보면 좋아요 개수가 한 자리 수까지 정확하게 표시되지 않습니다. 일정 크기의 단위로 끊어서 표시하는데요 여기에는 사용자의 편의성을 배려한 이유도 있을 수 있습니다. 실제로 사용자들은 좋아요가 몇 개인지 한 자리 수까지 그렇게 궁금하지 않을 것입니다. 이런 경우라면 sync schedule을 이용해 성능을 최적화 할 수 있을 것입니다.
'Study > 개발일지' 카테고리의 다른 글
| [백엔드온라인TIL] JPA 변경 감지 (50일차) (0) | 2023.08.03 |
|---|---|
| [백엔드온라인TIL] @RequiredArgsConstructor 를 사용할때 고려할점 (49일차) (0) | 2023.08.02 |
| [백엔드온라인TIL] JPA 학습 체크리스트 (47일차) (0) | 2023.07.31 |
| [백엔드온라인TIL] java 학습 46일차 (0) | 2023.07.28 |
| [백엔드스터디WIL]9주차 학습일지 (0) | 2023.07.28 |

